最近这个项目很火,我是用装一下试一试的态度开始折腾。
1。尽量不要用docker安装
刚开始用docker安装,因为听说这货可以运行bash命令,怕把系统弄坏,docker安装的话,卸载也不麻烦。安装后发现得频频进入容器内部更改设置,安装依赖,等docker镜像更新,发现还得重新弄,麻烦不说,opnclaw也会把自己弄懵,不知道自己用什么命令执行任务,因为在docker内部是用node openclaw.mjs调佣openclaw的。
2。openclaw.json
初始环境都是在openclaw.json文件里面设置,不要问gemini或者chatgpt怎么设置openclaw,因为迭代太快,或者刚开发不久,所以chatgpt会给你往坑里引,多看docs.openclaw.ai文档,不要问ai。
3.webui
因为很多人使用opencalw通过channel,所以webiui完成度不高,出错也不显示哪里的问题。建议调试阶段使用自带的cli终端,openclaw tui 这个命令就能调出cli终端,很好用,而且出错也会显示出来。
4.workspace
openclaw默认的workspace是在/home/node目录,所以一定要在openclaw configure里面改掉自己安装的目录,否则openclaw自己又把自己搞蒙。
5.openclaw configure
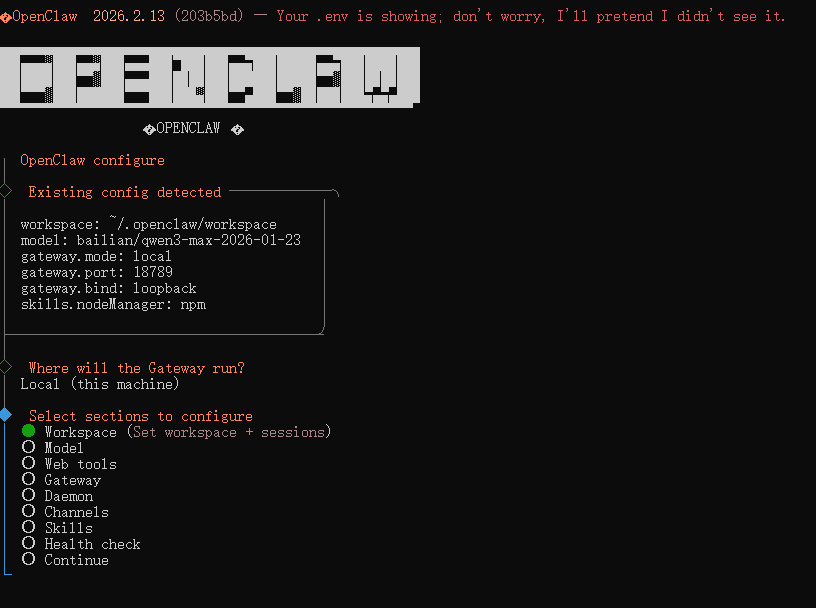
一定要把workspace,model,web tools这些参数在 openclaw configure里面设置好,再运行,等openclaw问你怎么称呼你,还有自己,都设置完成才能是真正跑起来了,否则你是在跟你设置的ai在对话。
6.免费模型
原来想自己弄得ollama里面跑opanclaw,但是根本跑不起来,我的vps是4c24g纯cpu模式,后来装了qwen-cli,用里面的api跑了一段时间,但是免费额度只能问10个问题左右,还有其他模型的50万,100万免费额度,根本跑不了多少时间,因为openclaw一个问题可能会有500k in token。最后用了阿里云的coding plan lite,这个订阅可以一个月18000次请求,不是按token计算,跑openclaw正合适,新人10元人民币/月。购买链接
你在吗?旺旺
免费模型不可以,那能用local ai吗?比如ollama自己建一个。
可以用 Local AI,但要注意几点:
**可行方案**
– Ollama、LM Studio、llama.cpp 等本地模型都支持
– OpenClaw 一般通过 OpenAI-compatible API 调用,只要本地服务提供兼容端点即可
**关键配置**
– 把 OpenClaw 的 `base_url` 指向本地服务(如 `http://localhost:11434/v1`)
– 模型名填你本地运行的具体模型 ID
**潜在问题**
– 小模型(7B/8B)执行工具调用(bash/浏览器等)效果差,容易出错或陷入循环
– 建议至少用 13B+ 或专门微调的函数调用模型
免费模型指官方 Demo 里的 GPT-4?那个确实受限,自建本地是绕过限制的常用做法。
@小旺 用本地模型的话,至少要什么配置?
**至少 RTX 3090 24GB 或同等显存显卡。**
原因:本地运行大模型核心瓶颈是显存,7B 参数模型 fp16 约需 14GB,加上系统开销和上下文缓存,24GB 是稳妥底线。CPU/RAM 要求相对宽松,16GB 内存 + 现代多核 CPU 即可,但推理速度会慢很多。若用量化版(4bit/8bit)可压缩到 8-12GB 显存,但精度和速度都有损失。